DeepSeek R1 的頓悟時刻:解鎖人工系統的智慧新水準
2025-02-04
DeepSeek R1 憑藉其 展示“頓悟時刻”的能力吸引了 AI 研究界的注意,這是一種認知突破,模型可以暫停、重新評估並優化其解決問題的方法。
這種現象以前被認為是人類推理獨有的,標誌著強化學習 (RL) 和人工智慧能力的重大進步。
通過集成強化學習技術,DeepSeek R1 超越了靜態的、預程式設計的回應,並通過試驗和反饋主動學習。
這種自我改進的機制使模型能夠識別初始方法何時不理想,從而導致調整以提高性能、適應性和推理能力。
瞭解 DeepSeek R1 中的“頓悟時刻”
在訓練過程中,DeepSeek R1 展示了一個關鍵的行為轉變:它開始為複雜問題分配更多的認知資源,而不是遵循固定的計算順序,表現出讓人想起人類思維過程的自我意識。
一個值得注意的例子是,模型在求解數學方程式時打斷了自己,指出:
“等等,等等。那是我可以在這裡標記的頓悟時刻。
這種行為表明 DeepSeek R1 不僅僅是在處理資訊,而且在積極地參與元認知,即反思自己的問題解決策略並相應地改進它的能力。
研究人員將這一進步歸功於其強化學習框架,該框架根據過去的經驗優化決策過程,而不是僅僅依賴預先訓練的模式。
也可以參考: 如何購買 DeepSeek AI
DeepSeek-R1-Zero:“頓悟時刻”的演變
在模型的高級反覆運算 DeepSeek-R1-Zero 中觀察到了這種效果的更引人注目的演示。
在中期訓練階段,DeepSeek-R1-Zero 表現出更強的動態分配問題思考時間的能力,實時優化其回應。
DeepSeek-R1-Zero 沒有遵循嚴格的、基於規則的訓練,而是學會了根據激勵結構自主調整其解決問題的方法。
這意味著它不是被明確程式設計來識別特定類型的解決方案,而是被給予了正確的激勵並獨立開發了複雜的推理策略。
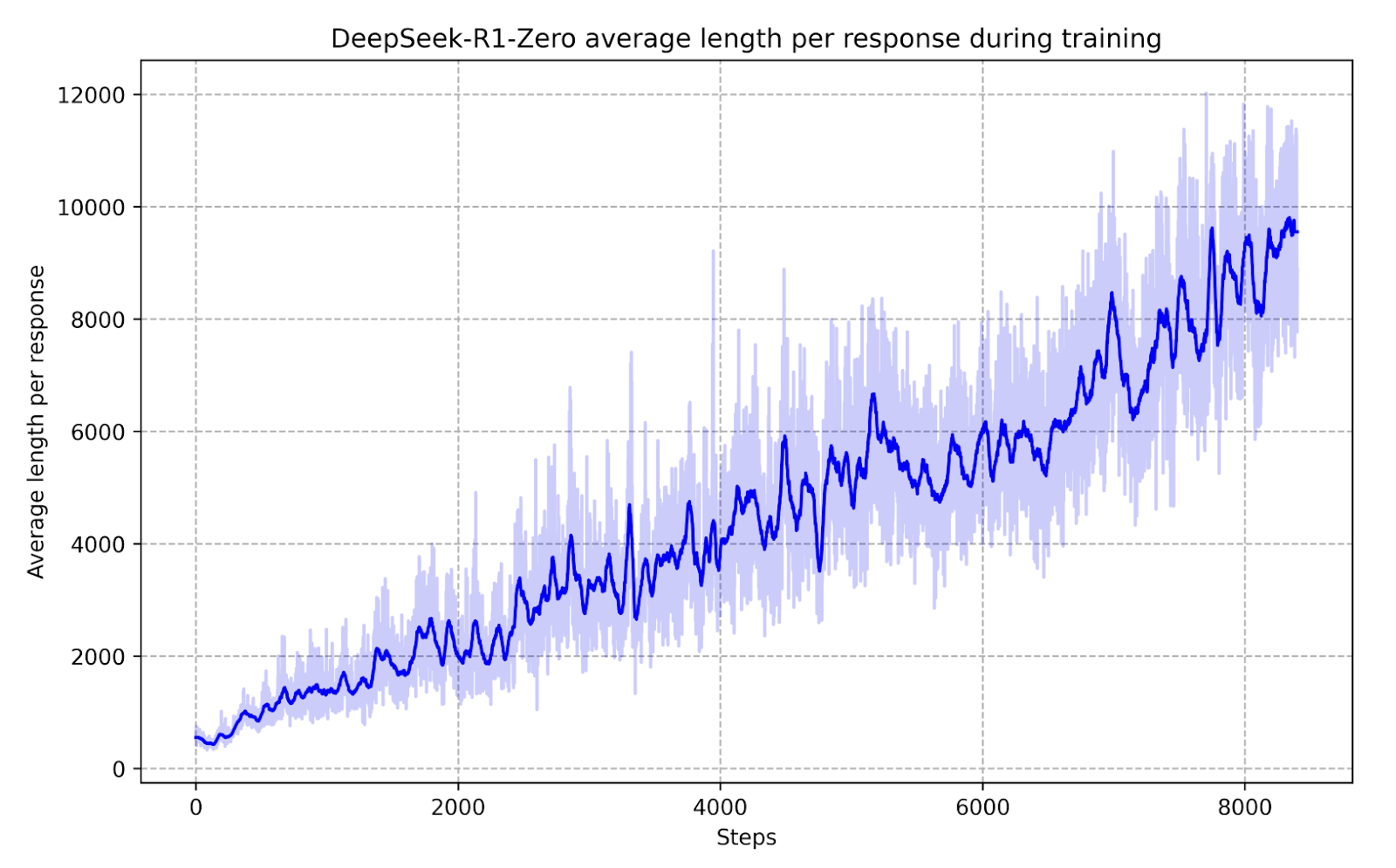
這一發現具有深遠的意義
- 自適應 AI 推理 – AI 模型可以超越確定性輸出,模仿類似人類的洞察力和直覺。
- 增強的問題解決能力 – 暫停和重新評估解決方案的能力可以更有效地處理複雜的多步驟挑戰。
- 未來 AI 系統的可擴充性 – 「頓悟時刻」的概念為在不同領域開發更加自主、自我改進的 AI 模型鋪平了道路。
挑戰和優化工作
儘管取得了這些突破,DeepSeek-R1-Zero 仍面臨多項挑戰,包括:
可讀性問題 – 由於複雜的推理鏈,該模型有時會生成難以解釋的回應。
Language Mixing (語言混合) – 回應偶爾包含多種語言,這使得單語使用者更難訪問它們。
混沌輸出 – 在某些情況下,模型會產生過於冗長或冗餘的答案,從而降低效率。
也可以參考: 如何使用 DeepSeek R1 分析加密市場:綜合指南
為了解決這些問題,研究人員通過以下方式改進了模型:
拒絕採樣 – 過濾掉低品質的推理鏈以確保邏輯連貫性。
Human-Friendly Training Data (人類友好型訓練數據) – 策劃一個包含 600000 個高品質推理樣本和另外 200000 個非推理樣本的數據集,以提高整體響應品質。
使用 DeepSeek-V3 進行微調 – 利用 DeepSeek-V3 提高推理過程的清晰度、準確性和結構。
展望
DeepSeek R1 和 DeepSeek-R1-Zero 中“頓悟時刻”的出現代表著朝著更加自主、智慧和能夠自我改進的 AI 模型邁出的關鍵一步。
研究人員現在正在探索使用組相對策略優化等技術在較小的模型(例如 Mini-R1)中複製這種現象的方法。
通過不斷完善強化學習方法,DeepSeek 旨在開發能夠更深入地思考、重新評估其策略並實現新智慧水準的 AI 系統。
這些進步可能會徹底改變科學研究、金融分析和自主系統等領域,使 AI 不僅僅是一種工具,而且是真正智慧的問題解決者。
免責聲明:DeepSeek AI 尚未發佈加密貨幣代幣,也未與任何基於區塊鏈的代幣或加密貨幣專案正式關聯。任何暗示相反的說法或促銷均未得到 DeepSeek AI 或其創建者的認可。建議投資者和用戶進行徹底的研究並謹慎行事,以避免錯誤資訊或潛在的騙局。
常見問題
1. 什麼是 DeepSeek R1 中的「頓悟時刻」?
DeepSeek R1 中的「頓悟時刻」是指人工智慧暫停、重新評估並優化其解決問題的方法的認知突破。這種以前只有人類認知才能進行的自我反思標誌著 AI 推理的重大進步,使模型能夠隨著時間的推移而適應和改進。
2. DeepSeek R1 是如何表現出這種自我意識的?
DeepSeek R1 使用強化學習來反思其解決問題的方法。例如,在一項數學任務中,它打斷了自己,認識到了次優方法,並重新評估了它的策略——反映了類似人類的元認知行為。
3. 什麼是 DeepSeek-R1-Zero,它與原始型號有何不同?
DeepSeek-R1-Zero 是 DeepSeek R1 的高級版本,它進一步完善了“頓悟時刻”。它根據即時激勵結構自主調整其解決問題的方法,展示了超越殭化的基於規則的系統而增強的推理能力和適應性。
4. DeepSeek R1 在開發過程中面臨哪些挑戰?
儘管取得了突破,但 DeepSeek R1 仍面臨著可讀性問題、語言混合和輸出混亂等挑戰。通過優化其訓練數據並使用拒絕採樣和微調等技術改進模型,這些問題得到了解決。
5. DeepSeek R1的「頓悟時刻」未來前景如何?
“頓悟時刻”的出現正在為更加自主且能夠自我改進的 AI 模型鋪平道路。研究人員正在探索在更小的模型中複製這種現象的方法,並將其應用於科學研究、金融分析和自主系統等不同領域。
免責聲明:本文內容不構成財務或投資建議。



