Aha Moment в DeepSeek R1: открытие нового уровня интеллекта в искусственных системах
2025-02-04
DeepSeek R1 привлек внимание исследовательского сообщества в области искусственного интеллекта благодаря своей способности демонстрировать «момент ага» — когнитивный прорыв, когда модель делает паузу, переоценивает и оптимизирует свой подход к решению проблем.
Это явление, ранее считавшееся исключительным для человеческого мышления, знаменует собой значительный прогресс в обучении с подкреплением (RL) и возможностях искусственного интеллекта.
Интегрируя методы обучения с подкреплением, DeepSeek R1 выходит за рамки статических, заранее запрограммированных реакций и активно обучается с помощью проб и обратной связи.
Этот самосовершенствующийся механизм позволяет модели распознавать, когда первоначальный подход является неоптимальным, что приводит к корректировкам, повышающим производительность, адаптивность и способность к рассуждению.
Понимание «момента Ага» в DeepSeek R1
Во время обучения DeepSeek R1 продемонстрировал ключевой поведенческий сдвиг: вместо того, чтобы следовать фиксированной последовательности вычислений, он начал выделять больше когнитивных ресурсов на сложные проблемы, демонстрируя самосознание, напоминающее человеческие мыслительные процессы.
Примечательный пример этого произошел, когда модель, решая математическое уравнение, прерывала сама себя, заявив:
«Подождите, подождите. Это момент, который я могу здесь отметить».
Такое поведение говорит о том, что DeepSeek R1 не просто обрабатывает информацию, но активно участвует в метапознании, способности размышлять над собственной стратегией решения проблем и соответствующим образом совершенствовать ее.
Исследователи связывают этот прогресс с системой обучения с подкреплением, которая оптимизирует процессы принятия решений на основе прошлого опыта, а не полагается исключительно на предварительно обученные шаблоны.
Читайте также: Как купить DeepSeek AI
DeepSeek-R1-Zero: эволюция «момента Ага»
Еще более поразительная демонстрация этого эффекта наблюдалась в DeepSeek-R1-Zero, усовершенствованной итерации модели.
На промежуточных этапах обучения DeepSeek-R1-Zero продемонстрировал большую способность динамически распределять время на размышления о проблемах, оптимизируя свои ответы в режиме реального времени.
Вместо того, чтобы следовать жесткому обучению, основанному на правилах, DeepSeek-R1-Zero научилась автономно корректировать свой подход к решению проблем на основе структур стимулов.
Это означает, что вместо того, чтобы быть явно запрограммированным на распознавание конкретных типов решений, ему были предоставлены правильные стимулы и независимо разработанные сложные стратегии рассуждения.
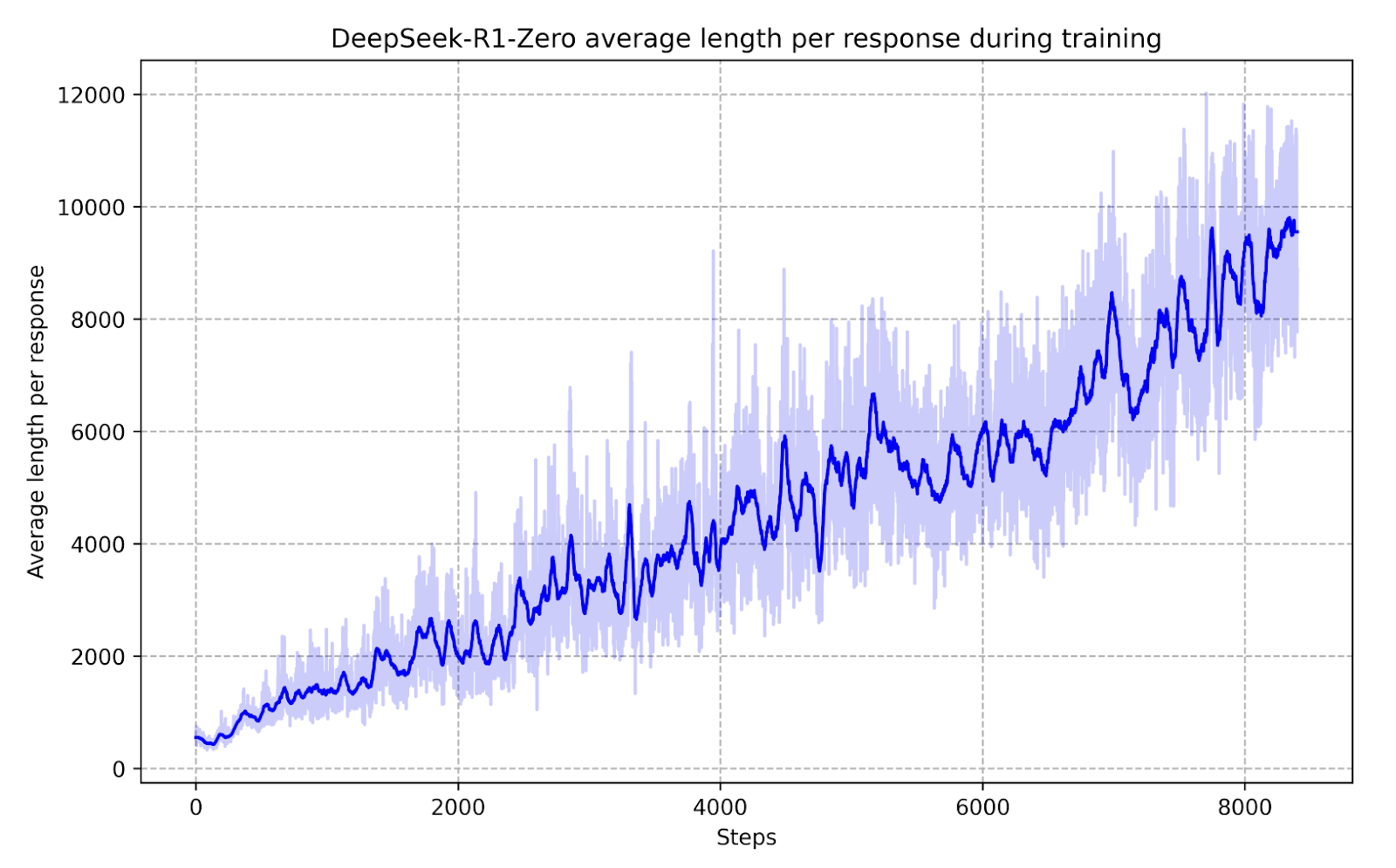
Это открытие имеет глубокие последствия
- Адаптивное мышление ИИ — модели ИИ могут развиваться за пределами детерминированных результатов, имитируя человеческую интуицию и понимание.
- Расширенные возможности решения проблем – Возможность приостанавливать и пересматривать решения позволяет более эффективно решать сложные, многоступенчатые задачи.
- Масштабируемость для будущих систем ИИ – Концепция «ага-момента» прокладывает путь к разработке более автономных, самосовершенствующихся моделей ИИ в различных областях.
Задачи и усилия по оптимизации
Несмотря на эти прорывы, DeepSeek-R1-Zero столкнулся с рядом проблем, в том числе:
Проблемы удобочитаемости — модель иногда генерировала ответы, которые было трудно интерпретировать из-за сложных цепочек рассуждений.
Смешение языков — ответы иногда включали несколько языков, что делало их менее доступными для одноязычных пользователей.
Хаотичные выходные данные – В некоторых случаях модель выдавала слишком длинные или избыточные ответы, что снижало эффективность.
Читайте также: Как анализировать крипторынок с помощью DeepSeek R1: подробное руководство
Чтобы решить эти проблемы, исследователи усовершенствовали модель за счет:
Выборка отбраковки — фильтрация цепочек рассуждений низкого качества для обеспечения логической согласованности.
Удобные для человека обучающие данные — курирование набора данных из 600 000 высококачественных выборок рассуждений и дополнительных 200 000 необоснованных выборок для улучшения общего качества ответов.
Тонкая настройка с помощью DeepSeek-V3 – Использование DeepSeek-V3 для повышения ясности, точности и структуры процессов рассуждения.
Перспективы
Появление «момента ага» в DeepSeek R1 и DeepSeek-R1-Zero представляет собой важный шаг на пути к моделям искусственного интеллекта, которые являются более автономными, интеллектуальными и способными к самосовершенствованию.
В настоящее время исследователи изучают способы воспроизведения этого явления в меньших моделях, таких как Mini-R1, используя такие методы, как оптимизация групповой относительной политики.
Постоянно совершенствуя методологии обучения с подкреплением, DeepSeek стремится разрабатывать системы искусственного интеллекта, которые могут мыслить более глубоко, пересматривать свои стратегии и достигать новых уровней интеллекта.
Эти достижения могут произвести революцию в таких областях, как научные исследования, финансовый анализ и автономные системы, сделав ИИ не просто инструментом, а по-настоящему интеллектуальным средством решения проблем.
Дисклеймер: DeepSeek AI не выпускал криптовалютный токен и не был официально связан с каким-либо токеном или криптовалютным проектом на основе блокчейна. Любые заявления или рекламные акции, предполагающие обратное, не одобряются DeepSeek AI или его создателями. Инвесторам и пользователям рекомендуется проводить тщательные исследования и проявлять осторожность, чтобы избежать дезинформации или потенциального мошенничества.
Вопросы и ответы
1. Что такое «ага-момент» в DeepSeek R1?
«Момент ага» в DeepSeek R1 относится к когнитивному прорыву, когда ИИ делает паузу, переоценивает и оптимизирует свой подход к решению проблем. Эта саморефлексия, ранее доступная исключительно человеческому познанию, знаменует собой значительный прогресс в мышлении ИИ, позволяя модели адаптироваться и улучшаться с течением времени.
2. Как DeepSeek R1 демонстрирует это самосознание?
DeepSeek R1 использует обучение с подкреплением для анализа методов решения проблем. Например, во время выполнения математической задачи он прервал сам себя, распознал неоптимальный подход и переоценил свою стратегию, отражая метакогнитивное поведение, подобное человеческому.
3. Что такое DeepSeek-R1-Zero, и чем он отличается от оригинальной модели?
DeepSeek-R1-Zero — это усовершенствованная версия DeepSeek R1, которая еще больше совершенствует «ага-момент». Она автономно корректирует свой подход к решению проблем на основе структур стимулов в режиме реального времени, демонстрируя расширенные возможности рассуждения и адаптивность за пределами жестких систем, основанных на правилах.
4. С какими трудностями столкнулся DeepSeek R1 при разработке?
Несмотря на свои прорывы, DeepSeek R1 столкнулся с такими проблемами, как проблемы с удобочитаемостью, смешивание языков и хаотичный вывод. Эти проблемы были решены путем уточнения обучающих данных и улучшения модели с помощью таких методов, как выборка отбраковки и тонкая настройка.
5. Каковы дальнейшие перспективы «ага-момента» DeepSeek R1?
Появление «ага-момента» прокладывает путь для моделей ИИ, которые являются более автономными и способными к самосовершенствованию. Исследователи изучают способы воспроизведения этого явления в меньших моделях и применения его в различных областях, таких как научные исследования, финансовый анализ и автономные системы.
Disclaimer: De inhoud van dit artikel vormt geen financieel of investeringsadvies.



